AlphaGo的胜利,犹如一道闪电划破了围棋领域的寂静,但DeepMind并未止步于此。他们如同勇攀高峰的探险家,将目光投向了更为深邃的领域——通过机器学习,他们打造了能够与人类并肩作战的《Quake III Arena》AI。在这场竞技中,DeepMind团队聚焦于“夺旗模式”,并巧妙地将地图设置成每场战斗后随机变化,为AI们带来了前所未有的挑战。它们不仅要迅速适应陌生环境,精准导航,更要学会与队友并肩作战,应对各种复杂的敌方战术。
然而,挑战远不止于此。AI的目标只有一个——胜利,但实现这一目标的路径却千变万化,这使得AI在判断何种行为更有利于胜利时陷入了困境。此外,每个AI玩家还需设定自己的“动机”,如跟随队友、夺取旗帜等。DeepMind不仅让AI之间相互对抗,还让它们与人类展开较量,从中学习人类的战术。令人惊讶的是,AI不仅学会了如何更好地合作,甚至还“偷学”了诸如埋伏等高级技巧。
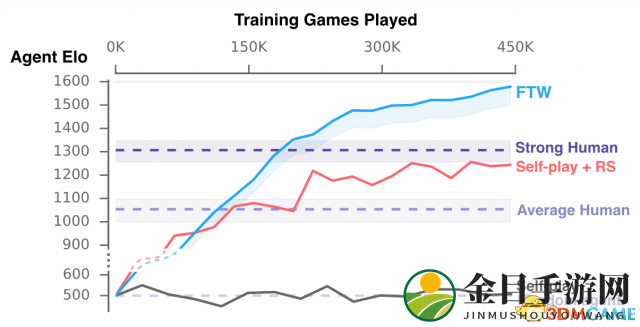
从表现来看,自己和自己随机玩的 AI 到不了一般人类的水准,但加上足够多的动机的话,可以在 20 万场「训练」之后,到达接近人类「高手」的程度。如果是再加上了和人类间的对抗的话,则可以在大约 15 万场后超过人类好手,并且继续向上爬升。
就最直观来说,这样的 AI 在近期内可能可以有助于电竞团队练习、并发现新的战术;如果训练系统可以更通用化的话,或许可以产生出一些真正厉害的电脑对手来呢。